Blog 3:Structured vs Unstructured Data
Data Overview
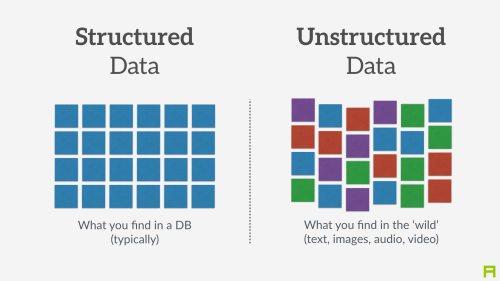
Structured Data is data that is represented in a
database, xml, csv, etc. It is easy for machines to process and allows for
computations to be run on the data to enrichen it or make it more meaningful.
When data is both structured and formatted, it can be easily loaded into
databases or data warehouses for queries and processing.(1)
Unstructured Data,
on the other hand, is this blog for
example. Usually data that is stored in human readable format that is easy for
us to understand but very difficult or impossible at times for a computer to
understand. Can be analyzed by computers via parsers and such, but it is much
easier for a human to put data into a structured format than it is for
computers to take unstructured data and turn it into something structured.

Data Types
Next, I will discuss three different types of data that are
frequently seen in business. Communication data for the most part is
unstructured but the metadata can be structured. Transactional data is mostly
structured and finally, log data can be structured as well. The graphic below highlights that the three
big sources of big data are transactions, emails(communications), and log data.
These three data types will be discussed in greater detail below.

(3)
Communication(email)
data is largely unstructured. It can be emails, text messages, phone calls,
or video calls. Even chatting with your bro Jim in the hall about the game last
night is communication. The actual communication itself is unstructured and
difficult to process, but records of communication can be aggregated in a
structured way. How frequently and for how long people communicate in business
can very well be loaded into a structured format. In most large organizations,
employees sign waivers allowing the organization to track communication data.
It can be loaded into a data warehouse and trends in communications can be
analyzed for investigation or business trends.
Transactional data by
nature is the most structured of the three data types being discussed.
Transactions are almost always tracked in a database and hold customer,
supplier, product, and sale data. All of this data can be easily loaded from a
transactional database into a data warehouse for processing and analyzing
metadata and trends. When in a transactional database, data is more than likely
in 3rd or 4th normal form. The goal in a data warehouse is
fast processing of large data sets and normalization often slows this process
so it is better to flatten data when loading the data into a data warehouse.
Log data takes on
many forms and big businesses generate tremendous amounts of logs every day.
Logs can be collected from operating systems, applications, servers, databases,
networking devices, and many other sources. Although this data is uniform for
many operating systems, it is often unstructured. Many organizations such as
Splunk make log aggregators that parse logs into structured formats. From there,
log data can be analyzed on many different levels.
Data Warehouse Limitations

(4)
Next I will discuss the difficulties or limitations of data warehouses when discussing different types of data. As you can see in the above image, data takes many different forms and is collected from many different locations in an organization. One limitation of a data warehouse is more an issue in the actual data that makes the data warehousing process very difficult: non-uniform data. When you have data coming from multiple sources, the likelihood that all data is uniform is unlikely and can cause performance issues in a data warehouse in the ETL process. Another limitation is the sheer amount of data. Especially with large organizations, they can accumulate terabytes of data every day and need a way to archive data in order to make sure that their data warehouses are performing adequately. The quality and amount of data and can be limiting to the effectiveness of data warehouses and their ability to run analysis of data in a reasonable amount of time.
Where Data Warehouses are Headed
In my opinion, data warehouses will be leveraged to make
macro predictions based on much more micro data. As our ability to process more
quickly and efficiently with physically smaller devices advances, we will be
able to aggregate much larger data sets and run analysis on relationships
between data in ways we thought were unimaginable years ago. Rather than
simulate the economic outcome of events, we will be able to store micro data on
such a large scale that we will be able to accurately model macro levels economic
change. With this, our ability to accurately predict how changes in GDP and
small production changes will have a local, state, and country impact.
Increasing the ability to compute with more efficiency and store data in
smaller physical formats allows us to analyze data on a very large scale.
(2)
http://40.media.tumblr.com/eeb915d280ffa91ccf48225b8e18a8c1/tumblr_inline_o21dfhttNl1sleek4_500.png
{kind=link}
{kind=link}
(4)
http://hadooptutorial.info/wp-content/uploads/2014/12/Data-ware-house-environment.png
***This blog was submitted for grade and not to be taken as a professional recommendation***
***This blog was submitted for grade and not to be taken as a professional recommendation***
No comments:
Post a Comment